Rabbit R1 hands-on: Already more fun and accessible than the Humane AI PinIt has a working, reliable screen and easy-to-use controls.By C. Low, 5 hours ago
The world's leading AI companies pledge to protect the safety of children onlineBy P. Dixit, 04.23.2024
Samsung's Galaxy S24 Ultra is on sale for its lowest price yet at Amazon and Best BuyBy A. Skorheim, 04.23.2024
The world's leading AI companies pledge to protect the safety of children onlineBy P. Dixit, 04.23.2024
Samsung's Galaxy S24 Ultra is on sale for its lowest price yet at Amazon and Best BuyBy A. Skorheim, 04.23.2024
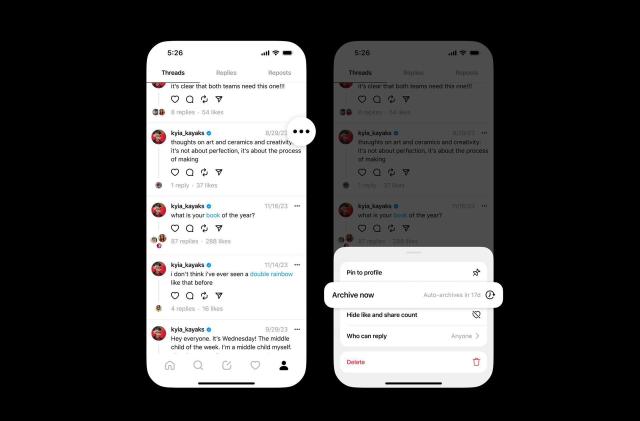
Threads has 150 million monthly usersMark Zuckerberg has speculated it could be Meta's next billion-user app.By K. Bell, 6 minutes ago
TikTok Lite axes ‘addictive as cigarettes’ reward-to-watch feature under the EU’s watchful eyeThe Digital Services Act’s regulatory muscles effectively forced the suspension.By W. Shanklin, an hour ago
PUBG will take a nostalgia-infused trip back to its first map in MayErangel Classic blends the “charmingly tacky” elements of the original with modern gameplay improvements.By W. Shanklin, 2 hours ago
JetBlue's in-flight entertainment system just got a watch party featureThe new platform also offers content recommendations and lets customers pick up from where they left off during a previous trip. By L. Bonk, 3 hours ago
WhatsApp is enabling passkey support on iOSYou'll soon be able to log in without an SMS passcode.By K. Holt, 4 hours ago
The White House wants a zero-emission freight industry by 2040It aims for 30 percent of the industry’s heavy truck sales to produce zero carbon emissions by 2030.By W. Shanklin, 4 hours ago
PBS Retro is a new FAST channel playing just the classicsIt offers 24/7 access to shows like Mister Rogers’ Neighborhood, Reading Rainbow and Zoboomafoo.By L. Bonk, 5 hours ago
Rabbit R1 hands-on: Already more fun and accessible than the Humane AI PinIt has a working, reliable screen and easy-to-use controls.By C. Low, 5 hours ago
Google has delayed killing third-party cookies from Chrome (again)Now the company says it’ll happen next year.By L. Bonk, 6 hours ago
Joe Biden signs the bill that could ban TikTok in the United StatesThe company has called the law “unconstitutional.” By K. Bell, 6 hours ago
Steam closes an early-access loophole in its refund policyAlmost any time played before a game’s release date now counts towards the two-hour limit. By K. Holt, 7 hours ago
Qualcomm is expanding its next-gen laptop chip line with the Snapdragon X PlusIt sits a tier below the X Elite while still featuring an NPU with up to 45 TOPS of performance.By S. Rutherford, 9 hours ago
Windows 11 now comes with its own adwareApp promotions in the startup menu are enabled by default, but can be turned off. By S. Dent, 9 hours ago
FTC bans employers from using noncompete clausesThey 'keep wages low, suppress new ideas and rob the American economy of dynamism.'By S. Dent, 10 hours ago
The best gifts for grads under $50Give them something useful without breaking the bank.By V. Palladino, 10 hours ago
Mercedes-Benz quad-motor G-Class could be the ultimate EV off-roaderWith four motors and some amazing tricks, the new G is a stunner.By T. Stevens, 10 hours ago
The Morning After: Senate passes the bill that could ban TikTokPresident Biden says he’ll sign the bill into law.By M. Smith, 11 hours ago
Mercedes-Benz finally unveils its electric G-Class luxury off-roaderThe G 580 with EQ Technology still looks like its gas-powered counterpart.By M. Moon, 11 hours ago
The best cheap fitness trackers for 2024Staying on top of your activity does not have to break the bank. By M. Saleh, 13 hours ago